用了这么久数据库,却不知道数据库是如何执行我们输入的语句的,经过一番查阅后,记录下执行一条查询和更新SQL语句后,MySQL是如何工作的。
SQL语句基本的执行链路:
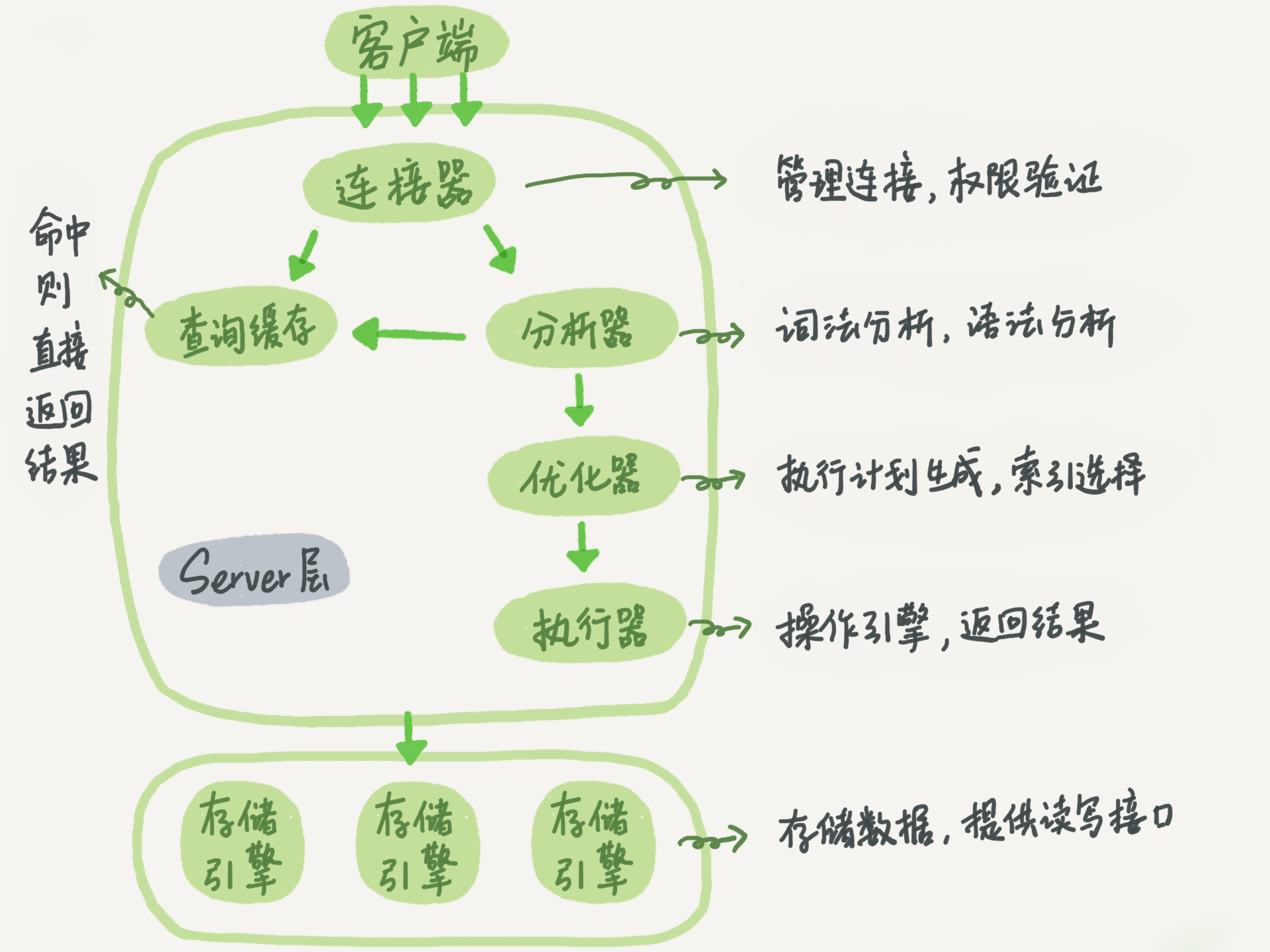
1 查询语句是如何执行
一条查询语句的执行过程一般是经过连接器、分析器、优化器、执行器等功能模块,最后到达存储引擎
2 更新语句是如何执行
一条更新语句的执行过程和查询的执行过程是一样的:
以执行这条SQL语句为例。1
mysql> update T set c=c+1 where ID=2;
- 连接器:连接数据库。
- 分析器:分析器通过词法和语法解析知道这是一条更新语句,
- 优化器:决定使用ID这个索引。
- 执行器:向存储引擎读取这一行数据,然后更新并写入存储引擎。
2 重要的日志模块
redo log
让我们继续以上面一条SQL语句为例,看看redo log是起到了什么作用。1
mysql> update T set c=c+1 where ID=2;
MySQL在执行这条语句时,肯定是先把ID=2这条数据从搜索引擎中拿出来,然后修改c字段,写入存储引擎,最后存储引擎刷入磁盘,这没问题吧?
MySQL的基本存储结构是页,所以MySQL是先把这条记录所在的页找到,然后再把该页的数据加载到内存,在内存中找到对应的数据后修改,再刷回磁盘。
问题1
如果在内存把数据修改了,但是还没来得及刷回磁盘数据库却突然岩机了怎么办?很显然数据就丢失了,这和我们预期的不一样。
如何解决
也许你会说很简单阿,在事务提交之前写入磁盘就行了。
问题2
如果每一次更新操作都需要刷回磁盘,这整个过程IO成本、查找记录成本都很高。一个页有16kb大小,只改一点内容就操作一次磁盘,为了解决这个问题。MySQL引入了WAL这么一个概念(Write-Ahead Logging),先写入日志,再写磁盘,至于什么时候再写入磁盘,会有配置供我们设置。
此时就引入redo log,当数据修改的时候,不仅在内存中操作,还会在redo log中记录这次操作,此时redo log的状态为prepare。当事务提交的时redo log日志将从prepare状态修改为commit,也就是我们所说的两阶段提交,然后再根据需要将更新完的数据刷入磁盘。当数据库岩机重启的时候,之前提交的记录都不会丢失,会恢复redo log中的内容到数据库,再根据undo log和binlog决定回滚还是提交数据。这个能力称为crash-safe。
redo log记录的是物理变化,即内容修改(在某个数据页上做了什么修改)。它也是需要磁盘的,但它的好处是顺序IO,比随机IO快多了。
undo log
undo log是用来保证事务的原子性,它记录数据被修改前的值,以便在事务失败的时候进行rollback。举个栗子,当事务提交成功后,在将redo log从perpare状态修改成commit时系统异常重启了,那么redo log会根据自身的状态并结合undo log进行回滚。
binlog
MySQL 整体来看,其实就有两块:一块是 Server 层,它主要做的是 MySQL 功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。redo log是InnoDB引擎特有的日志,而 Server 层也有自己的日志,称为 binlog(归档日志)。
binlog记录了数据库表结构和表数据变更,比如update/delete/insert/truncate/create。它不会记录select(因为这没有对表没有进行变更)。
我们可以简单理解为:存储着每条变更的SQL语句。
复制和恢复数据
主要有两个作用:
- MySQL在公司使用的时候往往都是一主多从结构的,从服务器需要与主服务器的数据保持一致,这就是通过binlog来实现的。
- 数据库的数据被干掉了,我们可以通过binlog来对数据进行恢复。
因为binlog记录了数据库表的变更,所以我们可以复制(主从复制)和恢复数据。
执行流程
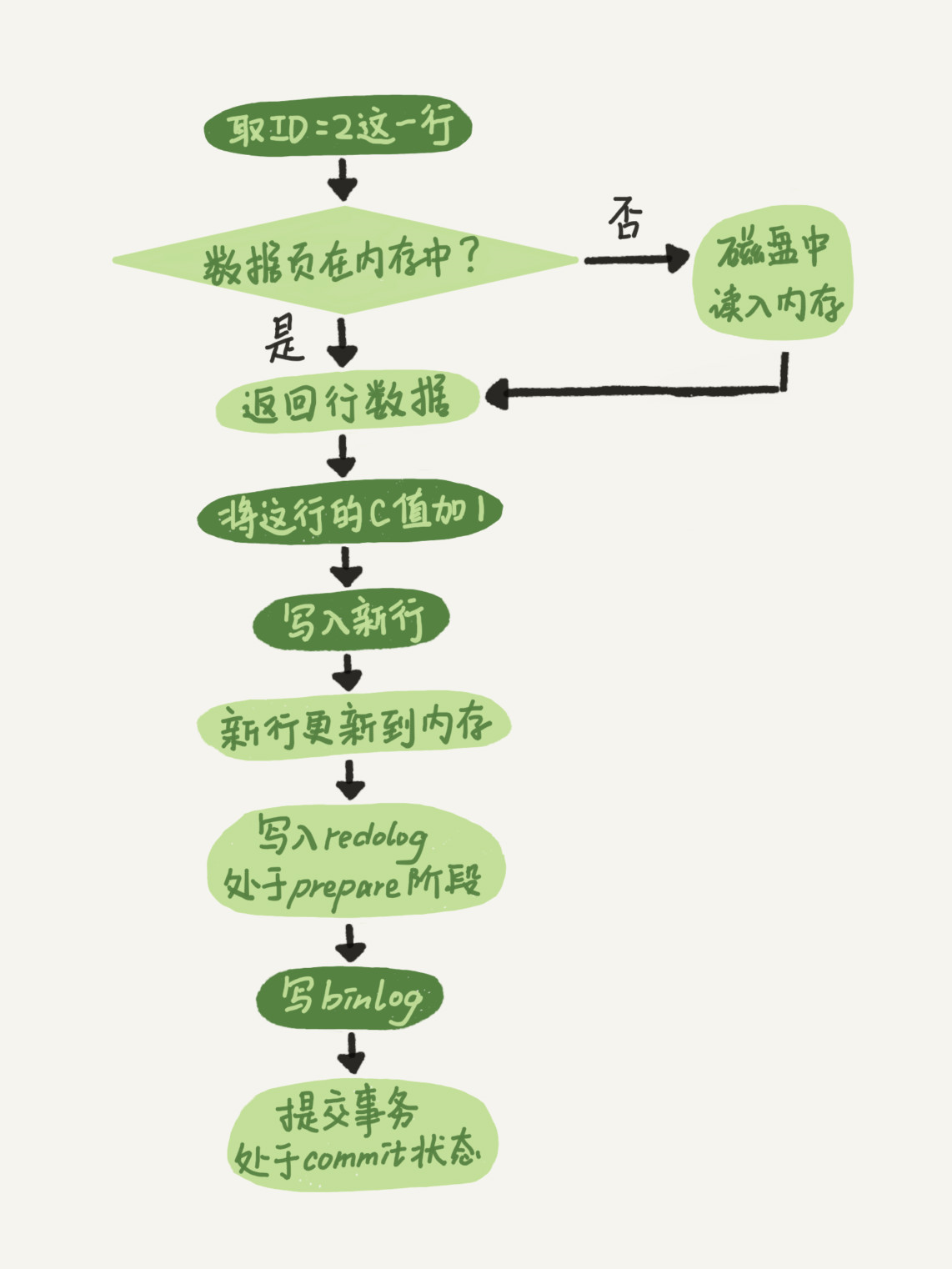
有了对这两个日志的概念性理解,我们再来看执行器和InnoDB引擎在执行上面简单的update语句时的内部流程。
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
update 语句的执行流程图:
3 redo log和binlog的不同
3.1 存储上
redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。
3.2 功能
redo log的作用是为持久化而生的。写完内存,如果数据库挂了,那我们可以通过redo log来恢复内存还没来得及刷到磁盘的数据,将redo log加载到内存里边,那内存就能恢复到挂掉之前的数据了。
binlog的作用是复制和恢复而生的。
主从服务器需要保持数据的一致性,通过binlog来同步数据。
如果整个数据库的数据都被删除了,binlog存储着所有的数据变更情况,那么可以通过binlog来对数据进行恢复。
那么如果整个数据库的数据都被删除了,那我可以用redo log的记录来恢复吗?
不能,因为功能的不同,redo log 存储的是物理数据的变更,如果我们内存的数据已经刷到了磁盘了,那redo log的数据就无效了。所以redo log不会存储着历史所有数据的变更,文件的内容会被覆盖的。
3.3 写入细节
redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎都可以使用。
参考资料:
- 极客时间,MySQL45讲