Kafka是一个分布式流处理平台a distributed streaming platform。以发布订阅的模式来记录流数据,类似于消息队列或企业级消息系统。下面引用官方文档的描述:
A streaming platform has three key capabilities:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
如何实现快速读写
- 顺序写(page cache)
- 零拷贝
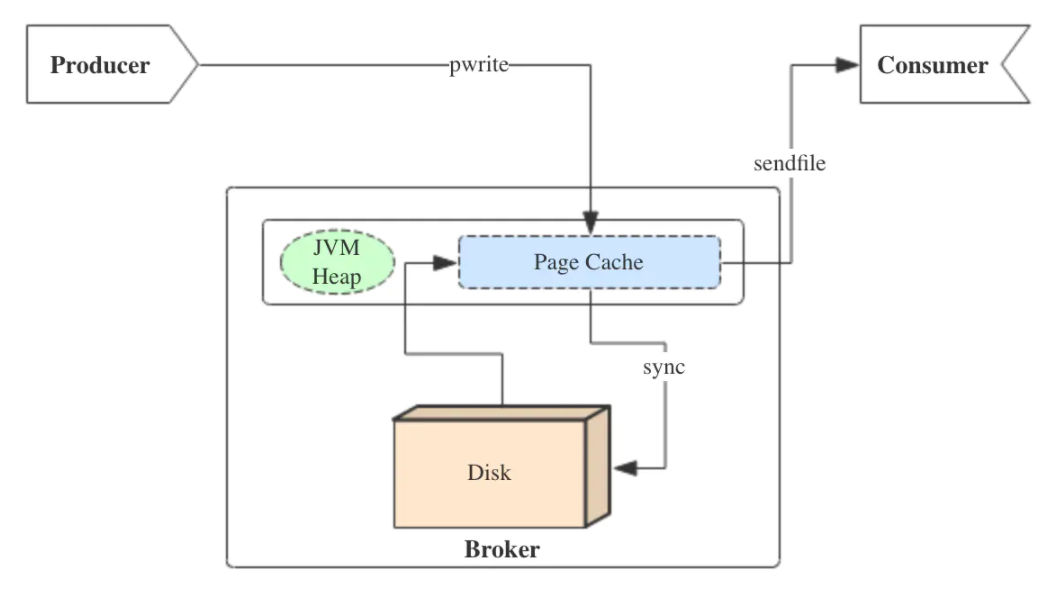
写入数据
Kafka在对磁盘写数据时采用了顺序写,每个Partition(分区)其实就是一个log文件。Producer 向对应的分区以追加写的方式写入文件末尾。这种方式相比随机写入要快很多。
实际上Kafka的数据并不是直接写到磁盘的,操作系统本身有一层缓存 page cache,当程序往文件中写数据时,会先写到ByteBuffer中,然后再提交到page cache中,此时程序由内核态返回至用户态告知写入成功,后续由操作系统自己把page cache里的数据刷入磁盘中。
通过这种相当于写入内存的方式提高了I/O效率。
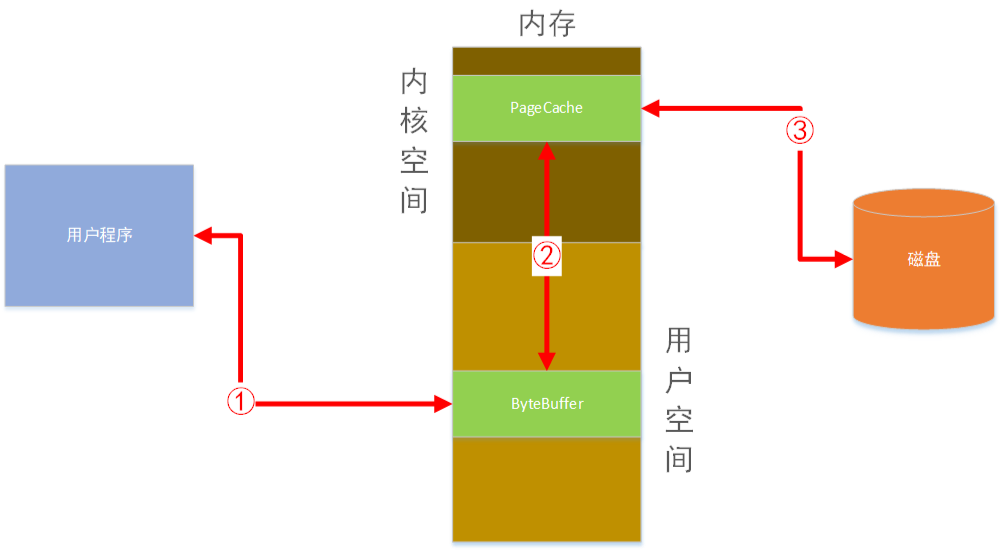
读取数据
现代unix操作系统提供了一种优化方式,可以将page cache中的数据直接传输到socket中,在Linux中可以通过调用系统提供的sendfile来实现。如果使用传统的往磁盘读数据的方式,会经过这几步:
- 调用
read(),操作系统从磁盘读取数据并写入内核态中的pagecache。 read()返回,应用程序将数据从内核态缓冲区拷贝至用户态缓冲区中。- 调用
write(),应用程序将数据从用户态缓冲区拷贝至内核态的套接字缓冲区中。 - 操作系统将数据从套接字缓冲区拷贝到
NIC缓冲区(网卡),然后通过网络发送。
以上传统读取数据的步骤,需要进过4次拷贝操作,很显然会影响读取的速度。Kafka通过使用sendfile,操作系统可以将page cache中的数据直接拷贝到网卡中,从而避免了重复拷贝。提高了读取性能。
1 | sendfile(socket, file, len); |
总结
Kafka之所以能够提供高并发的读取,主要是利用了磁盘的顺序写,并利用操作系统的page cache提高了磁盘I/O的效率;并运用了zore-copy技术,提升了整个系统的速度。